Offline Conflict Resolution
Detecting and resolving data conflicts when offline writes sync back to the server — version numbers, vector clocks, CRDTs (Automerge/Yjs), Background Sync API, and IndexedDB write queues.
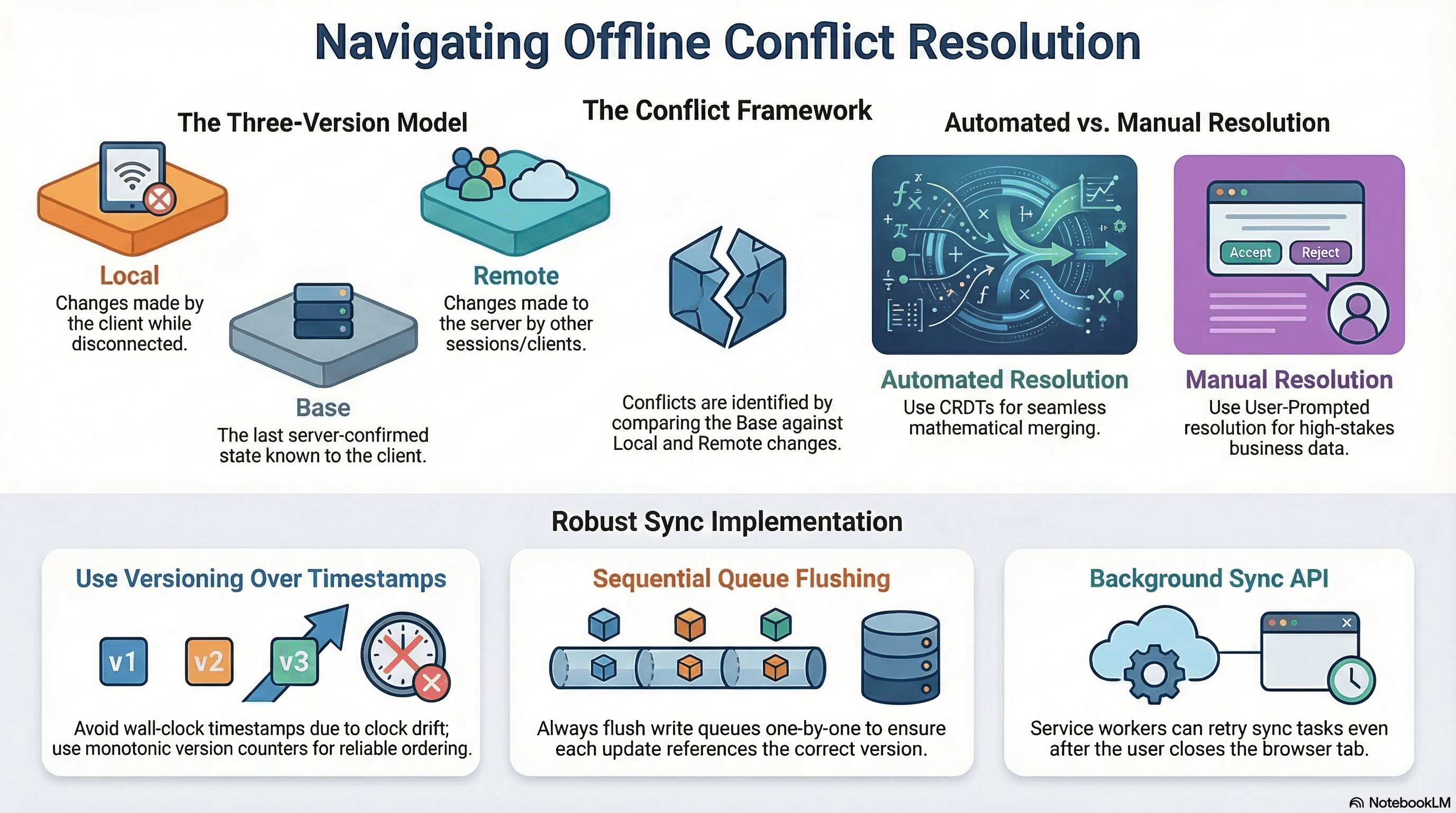
Overview
When a web application supports offline usage, users can make changes while disconnected. When they reconnect, local changes must sync to the server — but the server may have received conflicting updates from another client or session in the meantime.
Offline conflict resolution is the set of strategies for detecting these conflicts and deciding which version of data is correct — or how to merge both versions without data loss.
This matters for: service workers with background sync, local-first apps (PouchDB, Replicache, TinyBase), collaborative editing, and any app where the user continues interacting during poor connectivity.
How It Works
The Three-Version Model
Every conflict involves three versions of the same record:
| Version | Description |
|---|---|
| Base | The last server-confirmed state when the client last synced |
| Local | What the client changed while offline |
| Remote | What the server (or another client) changed meanwhile |
A conflict exists when both local and remote differ from base. If only one differs, it's a clean fast-forward — apply it directly.
Resolution Strategies
Last Write Wins (LWW) — the write with the latest timestamp wins. Simple, lossy. Clock skew on mobile devices makes timestamps unreliable as a tiebreaker.
Server Wins — discard client changes on conflict. Safe but frustrating — users lose offline work silently.
Client Wins — always apply client changes. Risk of overwriting valid server updates from other users.
Three-Way Merge — use base + local + remote to compute a merged result. Most correct, most complex.
User-Prompted Resolution — surface the conflict to the user with both versions and let them choose. Best for high-stakes data (document editing, customer records).
CRDTs — Conflict-free Replicated Data Types. Mathematical data structures where merge is always deterministic and commutative — no conflicts possible by design.
Code Examples
Version Numbers — Detecting Conflicts
Every record needs a monotonically increasing version (or updatedAt timestamp from the server). The client tracks the version it last saw. The server rejects updates that don't match the current version:
// server — Next.js route handler
// app/api/notes/[id]/route.ts
export async function PATCH(
request: Request,
{ params }: { params: { id: string } },
) {
const { content, clientVersion } = await request.json();
const current = await db.note.findUnique({ where: { id: params.id } });
if (!current) return Response.json({ error: "Not found" }, { status: 404 });
// clientVersion = the version the client was editing from
// current.version = what the server currently has
if (clientVersion !== current.version) {
// Conflict: server state has changed since the client's last sync
return Response.json(
{
error: "conflict",
serverVersion: current, // send server's current state
clientVersion: clientVersion, // echo the version client sent
},
{ status: 409 },
);
}
// No conflict — apply update and increment version
const updated = await db.note.update({
where: { id: params.id },
data: { content, version: current.version + 1 },
});
return Response.json(updated);
}IndexedDB Write Queue — Storing Offline Mutations
// lib/offline-queue.ts
// Stores pending writes in IndexedDB to survive page reloads and background sync
interface QueuedWrite {
id: string;
type: "note:update" | "task:create" | "task:update";
payload: Record<string, unknown>;
version: number; // server version the client was editing from
createdAt: number; // for ordering — flush sequentially
}
const DB_NAME = "offline-queue";
const STORE_NAME = "writes";
const DB_VERSION = 1;
function openDB(): Promise<IDBDatabase> {
return new Promise((resolve, reject) => {
const req = indexedDB.open(DB_NAME, DB_VERSION);
req.onupgradeneeded = (e) => {
const db = (e.target as IDBOpenDBRequest).result;
const store = db.createObjectStore(STORE_NAME, { keyPath: "id" });
store.createIndex("createdAt", "createdAt"); // ordered flush
};
req.onsuccess = () => resolve(req.result);
req.onerror = () => reject(req.error);
});
}
export async function enqueueWrite(
write: Omit<QueuedWrite, "id" | "createdAt">,
) {
const db = await openDB();
return new Promise<void>((resolve, reject) => {
const tx = db.transaction(STORE_NAME, "readwrite");
const store = tx.objectStore(STORE_NAME);
const entry: QueuedWrite = {
...write,
id: crypto.randomUUID(),
createdAt: Date.now(),
};
store.put(entry);
tx.oncomplete = () => resolve();
tx.onerror = () => reject(tx.error);
});
}
export async function getQueuedWrites(): Promise<QueuedWrite[]> {
const db = await openDB();
return new Promise((resolve, reject) => {
const tx = db.transaction(STORE_NAME, "readonly");
const store = tx.objectStore(STORE_NAME);
const index = store.index("createdAt");
const request = index.getAll();
request.onsuccess = () => resolve(request.result);
request.onerror = () => reject(request.error);
});
}
export async function removeQueuedWrite(id: string) {
const db = await openDB();
return new Promise<void>((resolve, reject) => {
const tx = db.transaction(STORE_NAME, "readwrite");
const store = tx.objectStore(STORE_NAME);
store.delete(id);
tx.oncomplete = () => resolve();
tx.onerror = () => reject(tx.error);
});
}Flushing the Queue — Sequential, Conflict-Aware
// lib/sync-manager.ts
import { getQueuedWrites, removeQueuedWrite } from "./offline-queue";
type ConflictResult = {
write: QueuedWrite;
serverVersion: Record<string, unknown>;
};
export async function flushQueue(): Promise<ConflictResult[]> {
const writes = await getQueuedWrites();
const conflicts: ConflictResult[] = [];
// CRITICAL: flush sequentially — parallel writes to the same record create races
// If writes A and B both target the same record, B must see A's result version
for (const write of writes) {
try {
const res = await fetch(`/api/${write.type.replace(":", "/")}`, {
method: "PATCH",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
...write.payload,
clientVersion: write.version,
}),
});
if (res.status === 409) {
// Conflict detected — queue for user resolution
const data = await res.json();
conflicts.push({ write, serverVersion: data.serverVersion });
// Don't remove from queue — user must resolve first
continue;
}
if (!res.ok) throw new Error(`Sync failed: ${res.status}`);
// Success — remove from queue
await removeQueuedWrite(write.id);
} catch (err) {
console.error("Sync error for write", write.id, err);
// Network error — leave in queue for next sync attempt
break; // stop flushing — try again when online
}
}
return conflicts;
}Background Sync API — Service Worker Queue
The Background Sync API lets a service worker register a sync task that the browser retries even after the page closes:
// In the page — register a sync when making a write
async function saveNoteOffline(
noteId: string,
content: string,
version: number,
) {
await enqueueWrite({
type: "note:update",
payload: { id: noteId, content },
version,
});
if (
"serviceWorker" in navigator &&
"sync" in ServiceWorkerRegistration.prototype
) {
const registration = await navigator.serviceWorker.ready;
// Register the sync — browser will call the SW's sync event
// even if the tab is closed (within browser-imposed limits)
await registration.sync.register("flush-write-queue");
}
}// public/sw.js — service worker handles the background sync event
self.addEventListener("sync", (event) => {
if (event.tag === "flush-write-queue") {
event.waitUntil(
// Import the sync function (dynamic import in SW context)
import("/sync-worker.js")
.then((m) => m.flushQueue())
.then((conflicts) => {
if (conflicts.length > 0) {
// Notify the page about conflicts via BroadcastChannel
const channel = new BroadcastChannel("sync-channel");
channel.postMessage({ type: "conflicts", conflicts });
}
}),
);
}
});// In the React app — listen for conflict notifications from the service worker
"use client";
import { useEffect, useState } from "react";
export function ConflictMonitor() {
const [conflicts, setConflicts] = useState<any[]>([]);
useEffect(() => {
const channel = new BroadcastChannel("sync-channel");
channel.onmessage = (e) => {
if (e.data.type === "conflicts") {
setConflicts(e.data.conflicts);
}
};
return () => channel.close();
}, []);
if (conflicts.length === 0) return null;
return (
<div role="alertdialog" aria-label="Sync conflicts">
<p>
{conflicts.length} conflict{conflicts.length !== 1 ? "s" : ""} need
resolution
</p>
{/* Render conflict UI per write */}
</div>
);
}CRDTs — Conflict-Free by Design
CRDTs (Conflict-free Replicated Data Types) are data structures whose merge operation is always commutative, associative, and idempotent — any order of merging produces the same result, with no conflicts possible.
Automerge (document-level CRDT):
import * as Automerge from "@automerge/automerge";
// Initialize a document on the server
let serverDoc = Automerge.init<{ title: string; body: string }>();
serverDoc = Automerge.change(serverDoc, (doc) => {
doc.title = "Meeting Notes";
doc.body = "Agenda: ...";
});
// Client A goes offline and edits the title
let clientA = Automerge.clone(serverDoc);
clientA = Automerge.change(clientA, (doc) => {
doc.title = "Q4 Planning Notes";
});
// Client B (online) edits the body simultaneously
let clientB = Automerge.clone(serverDoc);
clientB = Automerge.change(clientB, (doc) => {
doc.body = "Agenda: Q4 goals, budget review";
});
// Automerge merges deterministically — both changes are preserved
// No conflict: title from A, body from B
const merged = Automerge.merge(clientA, clientB);
// merged.title === "Q4 Planning Notes"
// merged.body === "Agenda: Q4 goals, budget review"Yjs (real-time collaborative text with CRDT):
import * as Y from "yjs";
import { WebrtcProvider } from "y-webrtc";
// Yjs Y.Text is a CRDT — concurrent edits merge without conflicts
const ydoc = new Y.Doc();
const ytext = ydoc.getText("document");
const provider = new WebrtcProvider("room-id", ydoc);
// Each client inserts at their cursor position — Yjs resolves concurrent insertions
ytext.insert(0, "Hello"); // Client A at position 0
ytext.insert(5, " World"); // Client B at position 5 (concurrent)
// Result: "Hello World" — deterministic regardless of network orderWhen to use CRDTs vs version-based conflict detection:
Use CRDTs when: multiple users edit the same document simultaneously (text editors, whiteboards, spreadsheets), you need automatic conflict-free merging, or the data type is naturally CRDT-friendly (counters, sets, text). Use version numbers + user resolution when: the data has business rules the merge can't know (financial records, inventory), a human must validate merged results, or a wrong merge has severe consequences (billing, medical records).
Vector Clocks — Causal Ordering Across Distributed Clients
Version numbers detect conflicts but don't capture causality. Vector clocks track which client saw which version — necessary when multiple clients make changes independently:
// Vector clock: { clientId: version }
// Each client tracks its own version + the last version it saw from each other client
type VectorClock = Record<string, number>;
function incrementClock(clock: VectorClock, clientId: string): VectorClock {
return { ...clock, [clientId]: (clock[clientId] ?? 0) + 1 };
}
function happensBefore(a: VectorClock, b: VectorClock): boolean {
// a happened before b if every component of a <= b and at least one is strictly <
const allKeys = new Set([...Object.keys(a), ...Object.keys(b)]);
let strictlyLess = false;
for (const key of allKeys) {
const av = a[key] ?? 0;
const bv = b[key] ?? 0;
if (av > bv) return false; // a has a component greater than b — not "before"
if (av < bv) strictlyLess = true;
}
return strictlyLess;
}
function isConcurrent(a: VectorClock, b: VectorClock): boolean {
// Concurrent if neither happened before the other
return !happensBefore(a, b) && !happensBefore(b, a);
}
// Usage: each write carries the client's vector clock
// Server uses isConcurrent() to determine if two writes conflictReal-World Use Case
Field inspection app. Field technicians use a tablet to complete inspection reports with poor or no signal. Reports are stored in IndexedDB. When connectivity returns, the Background Sync API fires flush-write-queue in the service worker — even if the tab is closed. The queue flushes sequentially (multiple edits to the same report preserve order). Reports with no server conflict are applied silently. One report was also updated by a supervisor in the office during the outage — a 409 is returned, a conflict object is stored, and BroadcastChannel notifies the React app. The technician sees the two versions side-by-side and selects the correct one.
Common Mistakes / Gotchas
1. Using client-side wall clock timestamps as the sole conflict arbiter. Mobile clocks drift, are set incorrectly, or are intentionally manipulated. A client with a 5-minute-fast clock always wins Last Write Wins — even if its data is stale. Use server-assigned timestamps or monotonic version counters for ordering.
2. Flushing the write queue in parallel. Promise.all() on the queue sends all writes simultaneously. Two writes to the same record race — neither sees the other's version update. Always flush sequentially: for (const write of writes) { await flush(write); }.
3. Silently discarding conflicts. "Server wins" discards user's offline work silently. If a user spent time editing offline and their changes are overwritten without explanation, they lose trust in the application. Surface conflicts to the user whenever the data is human-authored.
4. Not tracking the base version at write time. To detect a conflict, the server needs to know which version the client was editing from. If you don't store the clientVersion in the queued write, you can't send it later — you lose the ability to detect conflicts.
5. Expiring the queue after a short time. A technician might be in a no-signal area for 8 hours. If the IndexedDB queue expires after 1 hour, their offline changes are lost on reconnect. Queue entries should persist until successfully synced or explicitly discarded by the user.
Summary
Offline conflict resolution requires detecting that two versions of the same record have diverged and deciding how to reconcile them. Version numbers on every record make conflicts detectable — the server rejects writes where clientVersion !== currentVersion. IndexedDB stores pending writes durably across page reloads; Background Sync API triggers flush even when the page is closed. CRDTs (Automerge, Yjs) auto-merge data structures where conflicts are mathematically impossible — the right choice for collaborative editing. Vector clocks track causal relationships between writes from different clients, enabling precise conflict detection when simple version numbers aren't sufficient. Always flush the write queue sequentially, not in parallel. Never silently discard offline user work.
Interview Questions
Q1. What is the three-version model for offline conflict detection and why is the "base" version necessary?
The three versions are: base (the last server-confirmed state the client knew when it went offline), local (what the client changed while offline), and remote (what the server or another client changed in the meantime). The base version is essential because it's the common ancestor — without it, you can't distinguish between a conflict and a fast-forward. If local and remote both differ from base, you have a genuine conflict. If only remote differs from base (local is unchanged), it's a clean fast-forward — apply the remote change. If only local differs from base, it's a clean local update — apply it. Without the base, you'd treat every divergence as a conflict, even when it's actually a clean update.
Q2. Why must a write queue be flushed sequentially rather than in parallel?
If a user made two edits to the same record offline (first changed the title, then changed the body), those writes are ordered in the queue. If flushed in parallel: both reads the same base version and both are applied to the server independently — but the second write might reference a version that the first write has already superseded. The server sees the second write's clientVersion and rejects it with a 409 conflict, even though it's a legitimate sequential edit. Sequential flushing ensures each write sees the result of the previous one — the body edit arrives after the title edit has incremented the server version, and references the correct new version.
Q3. What is the Background Sync API and why is it better than a visibilitychange or online event handler?
The Background Sync API lets a service worker register a sync task (registration.sync.register('tag')) that the browser will retry automatically — even if the tab is closed or the browser is in the background. The browser manages retry logic, respects battery and network conditions, and will fire the sync event once connectivity is available. visibilitychange and online event handlers only fire in the tab that's open — if the user closed the tab after going offline, pending writes are stuck until the user reopens the app. Background Sync ensures writes are flushed as soon as the device reconnects, even when the user isn't actively using the app.
Q4. What are CRDTs and what types of data are they well-suited for?
CRDTs (Conflict-free Replicated Data Types) are data structures with a merge operation that is commutative (order doesn't matter), associative (grouping doesn't matter), and idempotent (merging the same change twice has the same result as merging once). This guarantees that any two replicas that have seen the same set of operations will converge to the same state — without coordination, without conflicts. They're well-suited for: counters (G-Counter, PN-Counter), sets (G-Set, OR-Set — for adding/removing items), text (as in Automerge and Yjs, using a fractional indexing scheme), and key-value maps. They're unsuitable for data with complex cross-field business rules (a discount can't exceed the order total), or where a human needs to validate the merged result.
Q5. What is the difference between a version number and a vector clock for conflict detection?
A version number is a single integer that increments on every write. It detects that the server state changed since the client last synced — but it doesn't tell you which client made which change or in what order. For a single-server system with one active client at a time, this is sufficient. A vector clock is a map of { clientId: version } — each client tracks its own write counter and the last write counter it observed from each other client. Vector clocks capture causality: they can determine whether write A happened before B, B happened before A, or whether A and B are concurrent (neither could have seen the other). Concurrent writes are confirmed conflicts. Vector clocks are necessary in distributed systems with multiple clients writing simultaneously to the same data.
Q6. When should offline conflicts be automatically merged vs surfaced to the user?
Automatically merge when: the data type has a known, safe merge semantic (text edited by two users can be merged by a CRDT — final text contains both edits), the conflicting fields are independent (one user changed the title, another changed the body — both changes apply cleanly), or the consequence of an incorrect merge is low (a preference setting that either value is reasonable for). Surface to the user when: the data has cross-field business rules the merge algorithm can't know (financial records, inventory quantities — merging could result in an invalid business state), the data is high-stakes human-authored content (a legal document, a medical record), or the client and server versions represent genuinely different decisions by different people that require human judgment to reconcile. The general principle: automate merges when correctness can be guaranteed; require human review when it can't.
Idempotent UI Actions
How to design UI actions that produce the same result regardless of how many times they fire — client-side guards, server-side idempotency keys, React Strict Mode as an idempotency test, and why both layers are required.
Overview
How code travels from your editor to the browser — build tooling, bundle optimization, and delivery infrastructure.